Authors:
Yangchao Wu1, Yonatan Dukler2, Matthew Trager, Wei Xia, Alessandro Achille, Stefano Soatto
Abstract:Speculative decoding is a method for accelerating inference in large language models (LLMs) by predicting multiple tokens using a smaller ‘draft model’ and validating them against the larger ‘base model.’ If a draft token is inconsistent with what the base model would have generated, speculative decoding ‘backtracks’ to the last consistent token before resuming generation. This is straightforward in autoregressive Transformer architectures since their state is a sliding window of past tokens. However, their baseline inference complexity is quadratic in the number of input tokens. State Space Models (SSMs) have linear inference complexity, but they maintain a separate Markov state that makes backtracking non-trivial. We propose two methods to perform speculative decoding in SSMs: “Joint Attainment and Advancement” and “Activation Replay.” Both methods utilize idle computational resources to speculate and verify multiple tokens, allowing us to produce 6 tokens for 1.47⇥ the cost of one, corresponding to an average 1.82⇥ wall-clock speed-up on three different benchmarks using a simple n-gram for drafting. Furthermore, as model size increases, relative overhead of speculation and verification decreases: Scaling from 1.3B parameters to 13B reduces relative overhead from 1.98⇥ to 1.22⇥. Unlike Transformers, speculative decoding in SSMs can be easily applied to batches of sequences, allowing dynamic allocation of resources to fill gaps in compute utilization and thereby improving efficiency and throughput with variable inference traffic.
Authors:
Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao
Abstract:Key-value (KV) caching has become the de-facto technique to accelerate generation speed for large language models (LLMs) inference. However, the growing cache demand with increasing sequence length has transformed LLM inference to be a memory bound problem, significantly constraining the system throughput. Existing methods rely on dropping unimportant tokens or quantizing entries group-wise. Such methods, however, often incur high approximation errors to represent the compressed matrices. The autoregressive decoding process further compounds the error of each step, resulting in critical deviation in model generation and deterioration of performance. To tackle this challenge, we propose GEAR, an efficient error reduction framework that augments a quantization scheme with two error reduction components and achieves near-lossless performance at high compression ratios. GEAR first applies quantization to majority of entries of similar magnitudes to ultra-low precision. It then employs a low-rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. By adeptly integrating three techniques, GEAR is able to fully exploit their synergistic potentials. Our experiments show that GEAR can maintain similar accuracy to that of FP16 cache with improvement up to 24.42% over the SOTA baselines at 2-bit compression. Additionally, compared to LLM inference with FP16 KV cache, GEAR can reduce peak-memory of up to 2.39×, bringing 2.1× ∼ 5.07× throughput improvement. Our code will be publicly available.
Authors:
Fabian Paischer, Lukas Hauzenberger, Thomas Schmied
Abstract:Foundation models (FMs) are pre-trained on large-scale datasets and then fine- tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to modulate the pre-trained weights via a low-rank adaptation (LoRA) of newly introduced weights. These weight matrices are usually initialized at random with the same rank for each layer across the FM, which results in suboptimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner, by computing singular value decomposition on activation vectors. Then, we initialize the new LoRA matrices with the obtained right-singular vectors. Finally, we re-distribute the ranks among layers to explain the maximal amount of variance across all layers. This assignment results in an adaptive allocation of ranks per weight matrix, and inherits all benefits of LoRA. We apply our new method, Explained Variance Adaptation (EVA), to a variety of fine-tuning tasks comprising language understanding and generation, image classification, and reinforcement learning. EVA consistently attains the highest average score across a multitude of tasks per domain.
Authors:
Michael Pieler, Marco Bellagente, Hannah Teufel, Duy Phung
Abstract:Recently published work on rephrasing natural text data for pre-training LLMs has shown promising results when combining the original dataset with the synthetically rephrased data. We build upon previous work by replicating existing results on C4 and extending them with our optimized rephrasing pipeline to the English, German, Italian, and Spanish Oscar subsets of CulturaX. Our pipeline leads to increased performance on stan- dard evaluation benchmarks in both the mono- and multilingual setup. In addition, we provide a detailed study of our pipeline, investigating the choice of the base dataset and LLM for the rephrasing, as well as the relationship between the model size and the performance after pre-training. By exploring data with different perceived quality levels, we show that gains decrease with higher quality. Furthermore, we find the difference in performance between model families to be bigger than between different model sizes. This highlights the necessity for detailed tests before choosing an LLM to rephrase large amounts of data. Moreover, we investigate the effect of pre-training with synthetic data on supervised fine-tuning. Here, we find in- creasing but inconclusive results that highly depend on the used benchmark. These results (again) highlight the need for better benchmarking setups. In summary, we show that rephrasing multilingual and low-quality data is a very promising direction to extend LLM pre-training data.
Authors:
Vui Seng Chua, Yujie Pan, Nilesh Jain
Abstract:We present Statistical Calibrated Activation Pruning (SCAP), a post-training acti- vation pruning framework that (1) generalizes sparsification by input activations of Fully-Connected layers for generic and flexible application across Transformers, and (2) features a simple Mode-Centering technique to pre-calibrate activation distributions for maximizing post-training sparsity. Our results demonstrate robust Pareto efficiency compared to prior methods, translating to a 1.5× additional LLM decoding speedup against CATS[12] at iso model quality. SCAP effectiveness is empirically verified across a wide range of models, including recent Transformer Decoders, MoE, Mamba2, Encoding Transformer, and pre-quantized models, high- lighting its practicality and scalability. The code is available here.
Authors:
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, Doyen Sahoo
Abstract:Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications. However, their increased computational and memory demands present significant challenges, especially when handling long sequences. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory con- sumption during inference. Unlike existing approaches that optimize the memory based on the sequence length, we identify substantial redundancy in the channel dimension of the KV cache, as indicated by an uneven magnitude distribution and a low-rank structure in the attention weights. In response, we propose T HIN K, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in KV cache memory costs by over 20% compared with vanilla KV cache eviction and quantization methods. For instance, T HIN K integrated with KIVI can achieve a 2.8× reduction in peak memory usage while maintaining nearly the same quality, enabling up to a 5× increase in batch size when using a single GPU. Extensive eval- uations on the LLaMA and Mistral models across various long-sequence datasets verified the efficiency of T HIN K, establishing a new baseline algorithm for efficient LLM deployment without compromising performance.
Authors:
Md Toki Tahmid, Haz Sameen Shahgir, Sazan Mahbub, Yue Dong, Md. Shamsuzzoha Bayzid
Abstract:Recent advancements in Transformer-based language models have spurred interest, in their use for biological sequence analysis. However, adapting models like BERT, is challenging due to sequence length, often requiring truncation for proteomics, and genomics tasks. Additionally, advanced tokenization and relative positional, encoding techniques for long contexts in NLP are often not directly transferable, to DNA/RNA sequences, which require nucleotide or character-level encodings, for tasks such as 3D torsion angle prediction, distance map prediction or sec-, ondary structure prediction. To tackle these challenges, we propose an adaptive, dual tokenimzation scheme for bioinformatics that utilizes both nucleotide-level, (NUC) and efficient BPE tokenizations. Building on the dual tokenization, we, introduce BiRNA-BERT, a 117M parameter Transformer encoder pretrained with, our proposed tokenization on 28 billion nucleotides across 36 million coding, and non-coding RNA sequences. The learned representation by BiRNA-BERT, generalizes across a range of applications. The BiRNA-BERT model achieves, state-of-the-art results in long-sequence downstream tasks, performs comparably, well in short-sequence tasks, and matches the performance in nucleotide-level, structural prediction tasks, of models six times larger in parameter size, while, requiring 27 times less pre-training compute. In addition, our empirical experi-, ments and ablation studies demonstrate that NUC is often preferable over BPE, for bioinformatics tasks, given sufficient VRAM availability. We further demon-, strate the applicability of the dual-pretraning and adaptive tokenization strategy, employing this concept on a DNA language model which provides comparable, performance to 66X compute heavy DNA language models. BiRNA-BERT can, dynamically adjust its tokenization strategy based on sequence lengths, utilizing, NUC for shorter sequences and switching to BPE for longer ones, thereby offering, for the first time, the capability to efficiently handle arbitrarily long DNA/RNA sequences.
Authors:
Yoonsang Lee, Minsoo Kim, Seung-won Hwang
Abstract:This paper studies the problem of information retrieval, to adapt to unseen tasks., Existing work generates synthetic queries from domain-specific documents to, jointly train the retriever. However, the conventional query generator assumes the, query as a question, thus failing to accommodate general search intents. A more, lenient approach incorporates task-adaptive elements, such as few-shot learning, with an 137B LLM. In this paper, we challenge a trend equating query and question,, and instead conceptualize query generation task as a “compilation” of high-level, intent into task-adaptive query. Specifically, we propose EGG, a query generator, that better adapts to wide search intents expressed in the BeIR benchmark. Our, method outperforms baselines and existing models on four tasks with underexplored, intents, while utilizing a query generator 47 times smaller than the previous state-, of-the-art. Our findings reveal that instructing the LM with explicit search intent is, a key aspect of modeling an effective query generator.
Authors:
Lawrence Stewart, Matthew Trager, Sujan Kumar Gonugondla, Stefano Soatto
Abstract:Speculative decoding aims to speed up autoregressive generation of a language, model by verifying in parallel the tokens generated by a smaller draft model. In, this work, we explore the effectiveness of learning-free, negligible-cost draft strate-, gies, namely N -grams obtained from the model weights and the context. While, the predicted next token of the base model is rarely the top prediction of these, simple strategies, we observe that it is often within their top-k predictions for small, k. Based on this, we show that combinations of simple strategies can achieve, significant inference speedups over different tasks. The overall performance is, comparable to more complex methods, yet does not require expensive preprocess-, ing or modification of the base model, and allows for seamless ‘plug-and-play’, integration into pipelines.
Authors:
Jan Ludziejewski, Jan Małaśnicki, Maciej Pióro, Michał Krutul, Kamil Ciebiera, Maciej Stefaniak, Jakub Krajewski, Piotr Sankowski, Marek Cygan, Kamil Adamczewski, Sebastian Jaszczur
Abstract:In this work, we introduce a novel approach for optimizing neural network training, by adjusting learning rates across weights of different components in Transformer, models. Traditional methods often apply a uniform learning rate across all network, layers, potentially overlooking the unique dynamics of each part. Remarkably,, our introduced Relative Learning Rate Schedules (RLRS) method accelerates the, training process by up to 23%, particularly in complex models such as Mixture, of Experts (MoE). Hyperparameters of RLRS can be efficiently tuned on smaller, models and then extrapolated to 27× larger ones. This simple and effective method, results in a substantial reduction in training time and computational resources,, offering a practical and scalable solution for optimizing large-scale neural networks.
Authors:
Nadav Timor, Jonathan Mamoui, Daniel Korati, Moshe Berchanskyi, Oren Peregi, Moshe Wasserblati, Tomer Galanti, Michal Gordon, David Harel
Abstract:Accelerating the inference of large language models (LLMs) is an important, challenge in artificial intelligence. This paper introduces distributed speculative, inference (DSI), a novel distributed inference algorithm that is provably faster than, speculative inference (SI) [Leviathan et al., 2023, Chen et al., 2023, Miao et al.,, 2023] and traditional autoregressive inference (non-SI). Like other SI algorithms,, DSI works on frozen LLMs, requiring no training or architectural modifications,, and it preserves the target distribution. Prior studies on SI have demonstrated, empirical speedups (compared to non-SI) but require a fast and accurate drafter, LLM. In practice, off-the-shelf LLMs often do not have matching drafters that are, sufficiently fast and accurate. We show a gap: SI gets slower than non-SI when, using slower or less accurate drafters. We close this gap by proving that DSI is, faster than both SI and non-SI—given any drafters. By orchestrating multiple, instances of the target and drafters, DSI is not only faster than SI but also supports, LLMs that cannot be accelerated with SI. Our simulations show speedups of off-, the-shelf LLMs in realistic settings: DSI is 1.29-1.92x faster than SI. Our code is, open-sourced: github.com/keyboardAnt/Distributed-Speculative-Inference
Authors:
João Monteiro, Étienne Marcotte, Pierre-André Noël, Valentina Zantedeschi, David Vázquez, Nicolas Chapados, Christopher Pal, Perouz Taslakian
Abstract:Prompts are often employed to condition decoder-only language model generation, on reference information. Just-in-time processing of a context is inefficient due to, the quadratic cost of self-attention operations, and caching is desirable. However,, caching transformer states can easily require almost as much space as the model, parameters. When the right context is not known in advance, caching the prompt, can be challenging. This work addresses these limitations by introducing models, that, inspired by the encoder-decoder architecture, use cross-attention to condition, generation on reference text without the prompt. More precisely, we leverage, pre-trained decoder-only models and only train a small number of added layers., We use Question-Answering (QA) as a testbed to evaluate the ability of our models, to perform conditional generation and observe that they outperform prompt-based, inference methods, are comparable to fine-tuned prompted LLMs, and drasti-, cally reduce the space footprint relative to standard KV caching by two orders of, magnitude. Specifically, we introduced XC-L LAMA which converts a pre-trained, L LAMA 2 into an encoder-decoder architecture by integrating cross-attention layers, interleaved in between existing self-attention layers.
Authors:
Mohammadreza Ardestani, Yllias Chali
Abstract:This study aimed to leverage graph information, particularly Rhetorical Structure, Theory (RST) and Co-reference (Coref) graphs, to enhance the performance of, our baseline summarization models. Specifically, we experimented with a Graph, Attention Network architecture to incorporate graph information. However, this, architecture did not enhance the performance. Subsequently, we used a simple, Multi-layer Perceptron architecture, which improved the results in our proposed, model on our primary dataset, CNN/DM. Additionally, we annotated XSum dataset, with RST graph information, establishing a benchmark for future graph-based, summarization models. This secondary dataset posed multiple challenges, revealing, both the merits and limitations of our models.
Authors:
Albert Kjøller Jacobsen, Teresa Dorszewski, Lenka Tětková, Lars Kai Hansen
Abstract:Self-supervised speech representation models, particularly those leveraging trans-, former architectures, have demonstrated remarkable performance on downstream, tasks. Recent studies revealed high redundancy of transformer layers, potentially, allowing for smaller models and more efficient inference. We perform a detailed, analysis of layer similarity in speech models, leveraging three similarity metrics., Our findings reveal a block-like structure of high similarity, suggesting significant, redundancy within the blocks along with two main processing steps that are both, found to be critical for maintaining performance. We demonstrate the effectiveness, of pruning transformer-based speech models without post-training, achieving up, to 40% reduction in transformer layers while maintaining 95% of the model’s, predictive capacity. Lastly, we show that replacing the transformer stack with a few, simple layers can reduce the network size by up to 95% and inference time by up to, 87%, significantly reducing the computational footprint with minimal performance, loss, revealing the benefits of model simplification for downstream applications.
Authors:
Jonathan Mamou, Oren Pereg, Daniel Korat, Moshe Berchansky, Nadav Timor, Moshe Wasserblat, Roy Schwartz
Abstract:Speculative decoding is commonly used for reducing the inference latency of, large language models. Its effectiveness depends highly on the speculation looka-, head (SL)—the number of tokens generated by the draft model at each iteration. In, this work we show that the common practice of using the same SL for all iterations, (static SL) is suboptimal. We introduce DISCO (DynamIc SpeCulation lookahead, Optimization), a novel method for dynamically selecting the SL. Our experiments, with four datasets show that DISCO reaches an average speedup of 10% compared, to the best static SL baseline, while generating the exact same text.
Authors:
Sudhanshu Agrawal, Wonseok Jeon, Mingu Lee
Abstract:Speculative decoding [1] is a powerful technique that attempts to circumvent the, autoregressive constraint of modern Large Language Models (LLMs). The aim of, speculative decoding techniques is to improve the average inference time of a large,, target model without sacrificing its accuracy, by using a more efficient draft model, to propose draft tokens which are then verified in parallel. The number of draft, tokens produced in each drafting round is referred to as the draft length and is often, a static hyperparameter chosen based on the acceptance rate statistics of the draft, tokens. However, setting a static draft length can negatively impact performance,, especially in scenarios where drafting is expensive and there is a high variance in the, number of tokens accepted. Adaptive Entropy-based Draft Length (AdaEDL) is a, simple, training and parameter-free criteria which allows for early stopping of the, token drafting process by approximating a lower bound on the expected acceptance, probability of the drafted token based on the currently observed entropy of the, drafted logits. We show that AdaEDL consistently outperforms static draft-length, speculative decoding by 10%-57% as well as other training-free draft-stopping, techniques by upto 10% in a variety of settings and datasets. At the same time, we, show that AdaEDL is more robust than these techniques and preserves performance, in high-sampling-temperature scenarios. Since it is training-free, in contrast to, techniques that rely on the training of dataset-specific draft-stopping predictors,, AdaEDL can seamlessly be integrated into a variety of pre-existing LLM systems.
Authors:
Zexin Chen, Chengxi Li, Xiangyu Xie, Parijat Dube
Abstract:This paper explores the potential of a small, domain-specific language model trained, exclusively on sports-related data. We investigate whether extensive training data, with specially designed small model structures can overcome model size constraints., The study introduces the OnlySports collection, comprising OnlySportsLM,, OnlySports Dataset, and OnlySports Benchmark. Our approach involves:, 1) creating a massive 600 billion tokens OnlySports Dataset from FineWeb,, 2) optimizing the RWKV-v6 architecture for sports-related tasks, resulting in a, 196M parameters model with 20-layer, 640-dimension structure, 3) training the, OnlySportsLM on part of OnlySports Dataset, and 4) testing the resultant, model on OnlySports Benchmark. OnlySportsLM achieves a 37.62%/34.08%, accuracy improvements over previous 135M/360M state-of-the-art models and, matches the performance of larger models such as SomlLM 1.7B and Qwen, 1.5B in the sports domain. Additionally, the OnlySports collection presents, a comprehensive workflow for building high-quality, domain-specific language, models, providing a replicable blueprint for efficient AI development across various, specialized fields.
Authors:
Ashwinee Panda, Vatsal Baherwani, Benjamin Thérien, Stephen Rawls, Sambit Sahu, Supriyo Chakraborty, Tom Goldstein
Abstract:Mixture of Experts (MoE) pretraining is more scalable than dense Trans-, former pretraining, because MoEs learn to route inputs to a sparse set of, their feedforward parameters. However, this means that MoEs only receive, a sparse backward update, leading to problems such as router load imbal-, ance where some experts receive more tokens than others. We present a, lightweight approximation method that gives the MoE a dense gradient, while only sparsely activating its parameters. A key insight into the design, of our method is that at scale, many tokens not routed to a given expert, may nonetheless lie in the span of tokens that were routed to that expert,, allowing us to create an approximation for the expert output of that token, from existing expert outputs. Our dense backpropagation outperforms stan-, dard TopK routing across multiple MoE configurations without increasing, runtime.
Authors:
Yun Zhu, Jia-Chen Gu, Caitlin Sikora, Ho Ko, Yinxiao Liu, Chu-Cheng Lin, Lei Shu, Liangchen Luo, Lei Meng, Bang Liu, Jindong Chen
Abstract:Large language models (LLMs) augmented with retrieval exhibit robust perfor-, mance and extensive versatility by incorporating external contexts. However,, the input length grows linearly in the number of retrieved documents, causing a, dramatic increase in latency. In this paper, we propose a novel paradigm named, Sparse RAG, which seeks to cut computation costs through sparsity. Specifically,, Sparse RAG encodes retrieved documents in parallel, which eliminates latency, introduced by long-range attention of retrieved documents. Then, LLMs selectively, decode the output by only attending to highly relevant caches auto-regressively,, which are chosen via prompting LLMs with special control tokens. It is notable, that Sparse RAG combines the assessment of each individual document and the, generation of the response into a single process. The designed sparse mechanism, in a RAG system can facilitate the reduction of the number of documents loaded, during decoding for accelerating the inference of the RAG system. Additionally,, filtering out undesirable contexts enhances the model’s focus on relevant context,, inherently improving its generation quality. Evaluation results of two datasets show, that Sparse RAG can strike an optimal balance between generation quality and, computational efficiency, demonstrating its generalizability across both short- and, long-form generation tasks.
Authors:
Yanyuan Qiao, Zheng Yu, Zijia Zhao, Sihan Chen, Mingzhen Sun, Longteng Guo, Qi Wu, Jing Liu
Abstract:Multimodal large language models (MLLMs) have gained considerable atten-, tion due to their ability to integrate visual and textual information, enhancing, understanding and providing context for complex tasks. While Transformer-based, architectures have been the dominant framework for MLLMs, recent studies sug-, gest that state space models (SSMs) like Mamba can achieve competitive or even, superior performance. However, no prior research has investigated the potential, of SSMs to replace Transformers in multimodal tasks, which are inherently more, challenging due to the heterogeneity of visual and language data and the com-, plexities of aligning these modalities. In this paper, we introduce VL-Mamba, the, first study to explore the application of state space models in multimodal learning, tasks. VL-Mamba leverages a pretrained Mamba language model as its core, and, we propose a novel MultiModal Connector (MMC) that incorporates a Vision, Selective Scan (VSS) module to improve visual sequence modeling. We empir-, ically explore how to effectively apply the 2D vision selective scan mechanism, for multimodal learning and the combinations of different vision encoders and, variants of pretrained Mamba language models. Our experiments across multiple, multimodal benchmarks demonstrate that VL-Mamba achieves competitive perfor-, mance against small MLLMs of similar size, and in some cases, surpasses larger, models such as the 7B and 13B versions of LLaVA-1.5. These results suggest that, state space models have the potential to serve as an alternative to Transformers in, multimodal learning tasks.
Authors:
Edoardo Cetin, Qi Sun, Tianyu Zhao, Yujin Tang
Abstract:We introduce Neural Attention Memory Models (NAMMs) to improve the performance and efficiency of transformer foundation models. NAMMs are evolved atop pre-trained transformers to provide different latent contexts containing the most relevant information for individual layers and attention heads. NAMMs are universally applicable to any model using self-attention as they condition exclusively on the attention matrices produced in each layer. NAMMs learned on a relatively small set of problems substantially improve performance across multiple unseen long-context language tasks while cutting the model’s input contexts up to a fraction of the original sizes, setting them apart from prior hand-designed KV cache eviction strategies that only aim to preserve model behavior. We show the generality of our conditioning enables zero-shot transfer of NAMMs trained only on language to entirely new transformer architectures even across input modalities, with their benefits carrying over to vision and reinforcement learning. Our source code is available at https://github.com/SakanaAI/evo-memory.
Authors:
R. Gnana Praveen, Jahangir Alam
Abstract:peaker Verification has achieved significant progress using advanced deep learning architectures, specialized for speech signals as well as robust loss functions. Recently, fusion of faces and voices received a lot of attention as they offer complementary relationship with each other, outperforming unimodal approaches. In this work, we have investigated the potential of Vision Transformers (ViTs), pre-trained on visual data, for audio-visual speaker verification. To cope with the challenges of large-scale training, we introduce the Latent Audio-Visual Vision Transformer (LAVViT) adapters, where we exploit the existing pre-trained models on visual data by training only the parameters of LAVViT adapters, without fine-tuning the original parameters of the pre-trained models. The LAVViT adapters are injected into every layer of the ViT architecture to effectively fuse the audio and visual modalities using a small set of latent tokens, thereby mitigating the quadratic computational cost of cross-attention across the modalities. The proposed approach further circumvents the need for modality-specific architectures by employing the same ViT architecture with shared pretrained weights for audio and visual modalities. The proposed approach has been evaluated by conducting extensive experiments on the Voxceleb1 dataset and shows promising performance using only a few trainable parameters.
Authors:
Harry Jake Cunningham, Marc Peter Deisenroth
Abstract:Hybrid attention architectures have shown promising success in both equipping, self attention with inductive bias for long-sequence modelling and reducing the, computational burden of transformers without sacrificing quality. This paper intro-, duces Composite Attention, a theoretical framework for analyzing the combination, of sequence mixing primitives in modern deep learning architectures. Utilizing the, definition of sequence mixers as structured linear maps, we formalize the composi-, tion of sequence mixing primitives as either sequential or recurrent composition.
Authors:
Shashank Rajput, Sean Owen, Ying Sheng, Vitaliy Chiley
Abstract:The size of the key-value (KV) cache plays a critical role in determining both the, maximum context length and the number of concurrent requests supported during, inference in modern language models. The KV cache size grows proportionally, with the number of attention heads and the tokens processed, leading to increased, memory consumption and slower inference for long inputs. In this work, we, explore the use of MixAttention, a model architecture modification closely related, to a blog published by Character.AI [Character.AI, 2024]. MixAttention combines, sliding window attention, where only a small subset of recent tokens is stored in, the KV cache, with KV cache sharing across layers. Our experiments demonstrate, that MixAttention significantly reduces memory usage and improves inference, speed without sacrificing model performance in both short and long-context tasks., We also explore various configurations of this architecture, identifying those that, maintain quality across evaluation metrics while optimizing resource efficiency.
Authors:
Parsa Kavehzadeh, Mohammadreza Pourreza, Mojtaba Valipour, Tianshu Zhu, Haoli Bai, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh
Abstract:Deployment of autoregressive large language models (LLMs) is costly, and as these models increase in size, the associated costs will become even more considerable. Consequently, different methods have been proposed to accelerate the token generation process and reduce costs. Speculative decoding (SD) is among the most promising approaches to speed up the LLM decoding process by verifying multiple tokens in parallel and using an auxiliary smaller draft model to generate the possible tokens. In SD, usually one draft model is used to serve a specific target model; however, in practice, LLMs are diverse, and we might need to deal with many target models or more than one target model simultaneously. In this scenario, it is not clear which draft model should be used for which target model, and searching among different draft models, or training customized draft models, can further increase deployment costs. In this paper, we first introduce a novel multi-target scenario for deployment of draft models for faster inference. Then, we present a novel more efficient sorted speculative decoding mechanism that outperforms regular baselines in multi-target setting. We evaluated our method on Spec-Bench in different settings including base models such as Vicuna 7B, 13B, and LLama Chat 70B. Our results suggest that our draft models perform better than baselines for multiple target models at the same time.
Authors:
Anton Frederik Thielmann, Soheila Samiee
Abstract:Recent advancements in tabular deep learning (DL) have led to substantial per-, formance improvements, surpassing the capabilities of traditional models. With, the adoption of techniques from natural language processing (NLP), such as lan-, guage model-based approaches, DL models for tabular data have also grown in, complexity and size. Although tabular datasets do not typically pose scalability, issues, the escalating size of these models has raised efficiency concerns. De-, spite its importance, efficiency has been relatively underexplored in tabular DL, research. This paper critically examines the latest innovations in tabular DL, with, a dual focus on performance and computational efficiency. The source code is, available at https://github.com/basf/mamba-tabular.
Authors:
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi
Abstract:We introduce OLMOE, a fully open, state-of-the-art language model leveraging, sparse Mixture-of-Experts (MoE). OLMOE-1B-7B has 7 billion (B) parameters, but uses only 1B per input token. We pretrain it on 5 trillion tokens and further, adapt it to create OLMOE-1B-7B-INSTRUCT. Our models outperform all available, models with similar active parameters, even surpassing larger ones like Llama2-, 13B-Chat and DeepSeekMoE-16B. We present novel findings on MoE training,, define and analyze new routing properties showing high specialization in our model,, and open-source all our work: model weights, training data, code, and logs.
Authors:
Mohammad Samragh, Minsik Cho, Iman Mirzadeh, Moin Nabi, Keivan Alizadeh Vahid, Devang Naik, Fartash Faghri, Mehrdad Farajtabar
Abstract:The pre-training phase of language models often begins with randomly initialized, parameters. With the current trends in scaling models, training their large number, of parameters can be extremely slow and costly. In contrast, small language models, are less expensive to train, but they often cannot achieve the accuracy of large, models. In this paper, we explore an intriguing idea to connect these two different, regimes: Can we develop a method to initialize large language models using, smaller pre-trained models? Will such initialization bring any benefits in terms, of training time and final accuracy? In this paper, we introduce HyperCloning, a, method that can expand the parameters of a pre-trained language model to those, of a larger model with increased hidden dimensions. Our method ensures that, the larger model retains the functionality of the smaller model. As a result, the, larger model already inherits the predictive power and accuracy of the smaller, model before the training starts. We demonstrate that training such an initialized, model results in significant savings in terms of GPU hours required for pre-training, large language models. Implementation of HyperCloning is available at https:, //github.com/apple/ml-hypercloning/tree/main.
Authors:
Moyang Liu, Kaiying Yan, Yukun Liu, Ruibo Fu, Zhengqi Wen Xuefei Liu, Chenxing Li
Abstract:The rapid growth of social media has led to the widespread dissemination of, misinformation across multiple content forms, including text, images, audio, and, video. Compared to unimodal misinformation detection, multimodal misinfor-, mation detection benefits from the increased availability of information across, multiple modalities. However, these additional features may introduce redundancy,, where overlapping or irrelevant information is included, potentially disrupting the, feature space and consequently impairing the model’s performance. To address, the issue, we propose a novel framework, Misinformation Detection Mixture of, Experts (MisD-MoE), which employs distinct expert models for each modality, and incorporates an adaptive feature selection mechanism using top-k gating and, Gumbel-Sigmoid. This approach dynamically filters relevant features, reducing re-, dundancy and improving detection accuracy. Extensive experiments on the FakeSV, and FVC-2018 datasets demonstrate that MisD-MoE significantly outperforms, state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the, respective datasets compared to baseline models.
Authors:
Woomin Song, Jihoon Tack, Sangwoo Mo, Seunghyuk Oh, Jinwoo Shin
Abstract:State-space models (SSMs) offer a promising architecture for sequence modeling,, providing an alternative to Transformers by replacing expensive self-attention with, linear recurrences. In this paper, we propose a simple yet effective trick to enhance, SSMs within given computational budgets by sparsifying them. Our intuition is, that tokens in SSMs are highly redundant due to gradual recurrent updates, and, dense recurrence operations block the delivery of past information. In particular,, we observe that upper layers of SSMs tend to be more redundant as they encode, global information, while lower layers encode local information. Motivated by this,, we introduce Simba, a hierarchical sparsification method for SSMs based on token, pruning. Simba sparsifies upper layers more than lower layers, encouraging the, upper layers to behave like highways. To achieve this, we propose a novel token, pruning criterion for SSMs, measuring the global impact of tokens on the final, output by accumulating local recurrences. We demonstrate that Simba outperforms, the baseline model, Mamba, with the same FLOPS in various natural language, tasks. Moreover, we illustrate the effect of highways, showing that Simba not only, enhances efficiency but also improves the information flow across long sequences.
Authors:
Namrata Shivagunde, Mayank Kulkarni, Giannis Karamanolakis, Jack FitzGerald, Yannick Versley, Saleh Soltan, Volkan Cevher, Jianhua Lu, Anna Rumshisky
Abstract:Large language models (LLMs) have achieved remarkable performance on var-, ious natural language processing tasks, but training LLMs at scale is extremely, resource-intensive, requiring substantial computational power, memory, and energy, consumption. This has motivated research into efficient training methods, particu-, larly during the pre-training phase. There are two main approaches to approximate, full-rank training which have emerged to address this challenge: low-rank model, decomposition (e.g., ReLoRA) and memory-efficient optimizers (e.g., GaLore). In, this work, we systematically evaluate both lines of research on a range of metrics,, including validation perplexity, memory usage and throughput. Additionally, we, propose improvements on both low-rank decomposition methods, by improving, the low-rank matrices decomposition and initialization, and memory efficient opti-, mizer methods via the introduction of error feedback and dynamic update steps., Our comprehensive evaluation under the same experimental setting shows that, our proposed optimizations outperform all previous methods, achieving almost, same throughput as full-rank training, saving 9% in memory traded off for a 1.5%, increase in validation perplexity.
Authors:
Kai Yang, Vahid Partovi Nia, Boxing Chen, Masoud Asgharian
Abstract:Lightweight language models, such as TinyBERT 14.5M, have emerged as a critical, area of research because of their implementation on resource-constrained hardware., These transformer models include significantly smaller parameter size, reduced, memory and computational requirements. These features make such models highly, suitable for deployment on small devices. We explore the concept of parameter, sharing between the key and query weight matrices of a transformer model. The, full query-key sharing which has already been proposed in the literature intro-, duces a fully-quadratic attention matrix, oversimplifies directional dependencies, and degrades pre-training loss. In contrast, partial parameter sharing balances, complexity reduction and performance retention. Partial parameter sharing effec-, tively addresses over-fitting while maintaining strong performance even with a, high degree of shared parameters up to 95%. This provides a promising strategy, for enhancing language models, specifically targeting small models.
Authors:
Ali Saheb Pasand, Pouya Bashivan
Abstract:Training and fine-tuning Large Language Models (LLMs) require significant mem-, ory due to the substantial growth in the size of weight parameters and optimizer, states. While methods like low-rank adaptation (LoRA), which introduce low-rank, trainable modules in parallel to frozen pre-trained weights, effectively reduce mem-, ory usage, they often fail to preserve the optimization trajectory and are generally, less effective for pre-training models. On the other hand, approaches, such as, GaLore, that project gradients onto lower-dimensional spaces maintain the training, trajectory and perform well in pre-training but suffer from high computational com-, plexity, as they require repeated singular value decomposition on large matrices. In, this work, we propose Randomized Gradient Projection (RGP), which outperforms, GaLore, the current state-of-the-art in efficient fine-tuning, on the GLUE task suite,, while being 74% faster on average and requiring similar memory.
Authors:
Vicky Zayats, Peter Chen, Melissa Ferrari, Dirk Padfield
Abstract:Integrating multiple generative foundation models, especially those trained on dif-, ferent modalities, into something greater than the sum of its parts poses significant, challenges. Two key hurdles are the availability of aligned data (concepts that, contain similar meaning but is expressed differently in different modalities), and, effectively leveraging unimodal representations in cross-domain generative tasks,, without compromising their original unimodal capabilities., We propose Zipper, a multi-tower decoder architecture that addresses these con-, cerns by using cross-attention to flexibly compose multimodal generative models, from independently pre-trained unimodal decoders. In our experiments fusing, speech and text modalities, we show the proposed architecture performs very com-, petitively in scenarios with limited aligned text-speech data. We also showcase the, flexibility of our model to selectively maintain unimodal (e.g., text-to-text genera-, tion) generation performance by freezing the corresponding modal tower (e.g. text)., In cross-modal tasks such as automatic speech recognition (ASR) where the output, modality is text, we show that freezing the text backbone results in negligible, performance degradation. In cross-modal tasks such as text-to-speech generation, (TTS) where the output modality is speech, we show that using a pre-trained speech, backbone results in superior performance to the baseline.
Authors:
Xiaofan Lu, Yixiao Zeng, Feiyang Ma, Zixu Yu, Marco Levorato
Abstract:Speculative Decoding (SD) is a technique to accelerate the inference of Large, Language Models (LLMs) by using a lower complexity draft model to propose, candidate tokens verified by a larger target model. To further improve efficiency,, Multi-Candidate Speculative Decoding (MCSD) improves upon this by sampling, multiple candidate tokens from the draft model at each step and verifying them, in parallel, thus increasing the chances of accepting a token and reducing gen-, eration time. Existing MCSD methods rely on the draft model to initialize the, multi-candidate sequences and use static length and tree attention structure for, draft generation. However, such an approach suffers from the draft and target, model’s output distribution differences, especially in a dynamic generation con-, text. In this work, we introduce a new version of MCSD that includes a target, model initialized multi-candidate generation, a dynamic sliced topology-aware, causal mask for dynamic length adjustment, and decision models to optimize early, stopping. We experimented with our method on Llama 2-7B and its variants and, observed a maximum 27.5% speedup compared to our MCSD baseline across three, benchmarks with Llama 2-7B as the target model and JackFram 68M as the draft, model. Additionally, we evaluate the effects of using the target model initialized, multi-candidate process with different draft models on output quality. Our original, code is available on GitHub.
Authors:
Amrit Khera, Rajat Ghosh, Debojyoti Dutta
Abstract:LLM alignment ensures that large language models behave safely and effectively, by aligning their outputs with human values, goals, and intentions. Aligning LLMs, employ huge amounts of data, computation, and time. Moreover, curating data, with human feedback is expensive and takes time. Recent research depicts the, benefit of data engineering in the fine-tuning and pre-training paradigms to bring, down such costs. However, alignment differs from the afore-mentioned paradigms, and it is unclear if data efficient alignment is feasible. In this work, we first aim, to understand how the performance of LLM alignment scales with data. We find, out that LLM alignment performance follows an exponential plateau pattern which, tapers off post a rapid initial increase. Based on this, we identify data subsampling, as a viable method to reduce resources required for alignment. Further, we propose, an information theory-based methodology for efficient alignment by identifying, a small high quality subset thereby reducing the computation and time required, by alignment. We evaluate the proposed methodology over multiple datasets, and compare the results. We find that the model aligned using our proposed, methodology outperforms other sampling methods and performs comparable to, the model aligned with the full dataset while using less than 10% data, leading to, greater than 90% savings in costs, resources, and faster LLM alignment.
Authors:
Bo Liu, Rui Wang, Lemeng Wu, Yihao Feng, Peter Stone, Qiang Liu
Abstract:Modern large language models are built on sequence modeling via next-token, prediction. While the Transformer remains the dominant architecture for sequence, modeling, its quadratic decoding complexity in sequence length poses a major, limitation. State-space models (SSMs) present a competitive alternative, offering, linear decoding efficiency while maintaining parallelism during training. However,, most existing SSMs rely on linear recurrence designs that appear somewhat ad, hoc. In this work, we explore SSM design through the lens of online learning,, conceptualizing SSMs as meta-modules for specific online learning problems., This approach links SSM design to formulating precise online learning objectives,, with state transition rules derived from solving these objectives. Based on this, insight, we introduce a novel deep SSM architecture, Longhorn, whose update, resembles the closed-form solution for solving the online associative recall problem., Our experimental results show that Longhorn outperforms state-of-the-art SSMs,, including the Mamba model, on standard sequence modeling benchmarks, language, modeling, and vision tasks. Specifically, Longhorn achieves a 1.8x improvement, in sample efficiency compared to Mamba, and can extrapolate over contexts that, are up to 16x longer during inference. The code is provided at https://github., com/Cranial-XIX/Longhorn.
Authors:
Harry Dong, Tyler Johnson, Minsik Cho, Emad Soroush
Abstract:Tensor parallelism provides an effective way to increase server large language, model (LLM) inference efficiency despite adding an additional communication, cost. However, as server LLMs continue to scale in size, they will need to be, distributed across more devices, magnifying the communication cost. One way to, approach this problem is with quantization, but current methods for LLMs tend, to avoid quantizing the features that tensor parallelism needs to communicate., Taking advantage of consistent outliers in communicated features, we introduce a, quantization method that reduces communicated values on average from 16 bits to, 4.2 bits while preserving nearly all of the original performance. For instance, our, method maintains around 98.0% and 99.5% of Gemma 2 27B’s and Llama 2 13B’s, original performance, respectively, averaged across all tasks we evaluated on.
Authors:
Luning Wang, Shiyao Li, Xuefei Ning, Zhihang Yuan, Shengen Yan, Guohao Dai, Yu Wang
Abstract:Large Language Models (LLMs) have been widely adopted to process long-context, tasks. However, the large memory overhead of the key-value (KV) cache poses, significant challenges in long-context scenarios. Existing training-free KV cache, compression methods typically focus on quantization and token pruning, which, have compression limits, and excessive sparsity can lead to severe performance, degradation. Other methods design new architectures with le ss KV overhead but, require significant training overhead. To address the above two drawbacks, we, further explore the redundancy in the channel dimension and apply an architecture-, level design with minor training costs. Therefore, we introduce CSKV, a training-, efficient Channel Shrinking technique for KV cache compression: (1) We first, analyze the singular value distribution of the KV cache, revealing significant, redundancy and compression potential along the channel dimension. Based on this, observation, we propose using low-rank decomposition for key and value layers, and storing the low-dimension features. (2) To preserve model performance, we, introduce a bi-branch KV cache, including a window-based full-precision KV cache, and a low-precision compressed KV cache. (3) To reduce the training costs, we, minimize the layer-wise reconstruction loss for the compressed KV cache instead, of retraining the entire LLMs. Extensive experiments show that CSKV can reduce, the memory overhead of the KV cache by 80% while maintaining the model’s long-, context capability. Moreover, we show that our method can be seamlessly combined, with quantization to further reduce the memory overhead, achieving a compression, ratio of up to 95%. Code is available at https://github.com/wln20/CSKV.
Authors:
Zain Sarwar, Ashwinee Panda, Benjamin Thérien, Stephen Rawls, Anirban Das, Kartik Balasubramanian, Berkcan Kapusuzoglu, Shixiong Zhang, Sambit Sahu, Milind Naphade, Supriyo Chakraborty
Abstract:We introduce StructMoE, a method to scale MoEs by augmenting experts, with dynamic capacity using structured matrices we call Low Rank Experts, (LoRE). These LoREs are selected on a per-expert and per-token basis using, a secondary router specific to every expert and are entangled with the, main expert in the up-projection phase of the expert before the activation, function. Empirically, we find this approach to outperform a parameter, matched MoE baseline in terms of loss on a held out validation set.
Authors:
Mingyu Derek Ma, Yanna Ding, Zijie Huang, Jianxi Gao, Yizhou Sun, Wei Wang
Abstract:Generative Language Models rely on autoregressive decoding to produce the output, sequence token by token. Many tasks such as preference optimization, require, the model to produce task-level output consisting of multiple tokens directly by, selecting candidates from a pool as predictions. Determining a task-level prediction, from candidates using the ordinary token-level decoding mechanism is constrained, by time-consuming decoding and interrupted gradients by discrete token selection., Existing works have been using decoding-free candidate selection methods to, obtain candidate probability from initial output logits over vocabulary. Though, these estimation methods are widely used, they are not systematically evaluated,, especially on end tasks. We introduce an evaluation of a comprehensive collection, of decoding-free candidate selection approaches on a comprehensive set of tasks,, including five multiple-choice QA tasks with a small candidate pool and four, clinical decision tasks with a massive amount of candidates, some with 10k+, options. We evaluate the estimation methods paired with a wide spectrum of, foundation LMs covering different architectures, sizes and training paradigms. The, results and insights from our analysis could inform the future model design.
Authors:
Theodore Glavas, Joud Chataoui, Florence Regol, Wassim Jabbour, Antonios Valkanas, Boris N. Oreshkin, Mark Coates
Abstract:The vast size of Large Language Models (LLMs) has prompted a search to optimize, inference. One effective approach is dynamic inference, which adapts the architec-, ture to the sample-at-hand to reduce the overall computational cost. We empirically, examine two common dynamic inference methods for natural language generation, (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only, model is significantly more robust to layer removal via layer skipping, as opposed, to early exit. We demonstrate the difficulty of using hidden state information, to adapt computation on a per-token basis for layer skipping. Finally, we show, that dynamic computation allocation on a per-sequence basis holds promise for, significant efficiency gains by constructing an oracle controller. Remarkably, we, find that there exists an allocation which achieves equal performance to the full, model using only 23.3% of its layers on average.
Authors:
Rambod Azimi, Rishav Rishav, Marek Teichmann, Samira Ebrahimi Kahou
Abstract:Large language models (LLMs) have demonstrated remarkable performance across, various downstream tasks. However, the high computational and memory require-, ments of LLMs are a major bottleneck. To address this, parameter-efficient fine-, tuning (PEFT) methods such as low-rank adaptation (LoRA) have been proposed to, reduce computational costs while ensuring minimal loss in performance. Addition-, ally, knowledge distillation (KD) has been a popular choice for obtaining compact, student models from teacher models. In this work, we present KD-LoRA, a novel, fine-tuning method that combines LoRA with KD. Our results demonstrate that, KD-LoRA achieves performance comparable to full fine-tuning (FFT) and LoRA, while significantly reducing resource requirements. Specifically, KD-LoRA retains, 98% of LoRA’s performance on the GLUE benchmark, while being 40% more com-, pact. Additionally, KD-LoRA reduces GPU memory usage by 30% compared to, LoRA, while decreasing inference time by 30% compared to both FFT and LoRA., We evaluate KD-LoRA across three encoder-only models: BERT, RoBERTa, and, DeBERTaV3. Code is available at https://github.com/rambodazimi/KD-LoRA.
Authors:
Sasha Doubov, Nikhil Sardana, Vitaliy Chiley
Abstract:Small, highly trained, open-source large language models are widely used due to, their inference efficiency, but further improving their quality remains a challenge., Sparse upcycling is a promising approach that transforms a pretrained dense model, into a Mixture-of-Experts (MoE) architecture, increasing the model’s parameter, count and quality. In this work, we compare the effectiveness of sparse upcycling, against continued pretraining (CPT) across different model sizes, compute budgets,, and pretraining durations. Our experiments show that sparse upcycling can achieve, better quality, with improvements of over 20% relative to CPT in certain scenarios., However, this comes with a significant inference cost, leading to 40% slowdowns, in high-demand inference settings for larger models. Our findings highlight the, trade-off between model quality and inference efficiency, offering insights for, practitioners seeking to balance model quality and deployment constraints.
Authors:
Taehyeon Kim, Hojung Jung, Se-Young Yun
Abstract:Speculative decoding (SD) has emerged as a promising approach to accelerate, inference in large language models (LLMs). This method drafts potential future, tokens by leveraging a smaller model, while these tokens are concurrently verified, by the target LLM, ensuring only outputs aligned with the target LLM’s predic-, tions are accepted. However, the inherent limitations of individual drafters, es-, pecially when trained on specific tasks or domains, can hinder their effectiveness, across diverse applications. In this paper, we introduce a simple yet efficient uni-, fied framework, termed MetaSD, that incorporates multiple drafters into the spec-, ulative decoding process to address this limitation. Our approach employs multi-, armed bandit sampling to dynamically allocate computational resources across, various drafters, thereby improving overall generation performance. Through ex-, tensive experiments, we demonstrate that our unified framework achieves superior, results compared to traditional single-drafter approaches.
Authors:
Ankur Kumar
Abstract:KV cache compression methods have mainly relied on scalar quantization tech-, niques to reduce the memory requirements during decoding. In this work, we apply, residual vector quantization, which has been widely used for high fidelity audio, compression, to compress KV cache in large language models (LLM). We adapt the, standard recipe with minimal changes to compress the output of any key or value, projection matrix in a pretrained LLM: we scale the vector by its standard deviation,, divide channels into groups and then quantize each group with the same residual, vector quantizer. We learn the codebook using exponential moving average and, there are no other learnable parameters including the input and output projections, normally used in a vector quantization set up. We find that a residual depth of, 8 recovers most of the performance of the unquantized model. We also find that, grouping non-contiguous channels together works better than grouping contiguous, channels for compressing key matrix and the method further benefits from a light, weight finetuning of LLM together with the quantization. Overall, the proposed, technique is competitive with existing quantization methods while being much, simpler and results in 5.5x compression compared to half precision.
Authors:
Habib Hajimolahoseini, Shuangyue Wen, Walid Ahmed, Yang Liu
Abstract:Tensor decomposition is a mathematically supported technique for data, compression. It consists of applying some kind of a Low Rank Decomposition, technique on the tensors or matrices in order to reduce the redundancy of the data., However, it is not a popular technique for compressing the AI models duo to the, high number of new layers added to the architecture after decomposition. Although, the number of parameters could shrink significantly, it could result in the model be, more than twice deeper which could add some latency to the training or inference., In this paper, we present a comprehensive study about how to modify low rank, decomposition technique in AI models so that we could benefit from both high, accuracy and low memory consumption as well as speeding up the training and, inference.
Authors:
Bhawna Paliwal, Deepak Saini, Mudit Dhawan, Siddarth Asokan, Nagarajan Natarajan, Surbhi Aggarwal, Pankaj Malhotra, Jian Jiao, Manik Varma
Abstract:Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-ofthe-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. We address this by proposing Crossencoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application’s need for scoring thousands of items per query and the limited capabilities of current crossencoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
Authors:
Abderrahim Fathan, Xiaolin Zhu, Jahangir Alam
Abstract:Using clustering-driven annotations to train a neural network can be a tricky task, because of label noise. In this paper, we propose a dynamic and adaptive label noise, filtering method, called AdaptiveDrop which combines both label noise cleansing, and correction simultaneously in cascade to combine their advantages. Contrary, to other label noise filtering approaches, our method filters noisy samples on the, fly from an early stage of training. We also provide a variant that incorporates, sub-centers per each class for enhanced robustness to label noise by continuously, tracking the dominant sub-centers via a dictionary table. AdaptiveDrop is a simple, general-purpose method, performed end-to-end in only one stage of training, can, be integrated with any loss function, and does not require training from scratch, on the cleansed dataset. We show through extensive ablation studies for the self-, supervised speaker verification task that our method is effective, benefits from, long epochs of iterative filtering and provides consistent performance gains across, various loss functions and real-world pseudo-labels.
Authors:
Nikhil Bhendawade, Irina Belousova, Qichen Fu, Henry Mason, Mohammad Rastegari, Mahyar Najibi
Abstract:Speculative decoding is a prominent technique to accelerate large language model inference by leveraging predictions from an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, draft models add significant complexity to inference systems. Recently several single model architectures viz. Medusa have been proposed to speculate tokens in non-autoregressive manner, however, their effectiveness is limited due to lack of dependency between speculated tokens. We introduce a novel speculative decoding method that integrates drafting within the target model by using Multi-stream attention and incorporates future token planning into supervised finetuning objective. To the best of our knowledge, this is the first parameter-efficient approach that scales well with an increasing number of downstream tasks while enhancing downstream metrics and achieving high acceptance rates, attributable to the interdependence among the speculated tokens. Speculative Streaming speeds up decoding by 1.9 - 3X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, while improving generation quality and using ∼10000X fewer extra parameters than alternative architectures, making it ideal for resource-constrained devices. Our approach can also be effectively deployed in lossless settings for generic chatbot applications that do not necessitate supervised fine-tuning. In such setups, we achieve 2.9 - 3.2X speedup while maintaining the integrity of the base model’s output.
Authors:
Saber Malekmohammadi, Golnoosh Farnadi
Abstract:A significant approach in natural language processing involves large-scale pre-, training models on general domain data followed by their adaptation to specific, tasks or domains. As models grow in size, full fine-tuning all of their parameters, becomes increasingly impractical. To address this, some methods for low-rank task, adaptation of language models have been proposed, e.g., LoRA and FLoRA. These, methods keep the pre-trained model weights fixed and incorporate trainable low-, rank decomposition matrices into some layers of the transformer architecture, called, adapters. This approach significantly reduces the number of trainable parameters, required for downstream tasks compared to full fine-tuning all parameters. In, this work, we look at low-rank adaptation from the lens of data privacy. We, show theoretically that the low-rank adaptation used in LoRA and FLoRA is, equivalent to injecting some random noise into the batch gradients w.r.t the adapter, parameters, and we quantify the variance of the injected noise. By establishing a, Berry-Esseen type bound on the total variation distance between distribution of, the injected noise and a Gaussian distribution with the same variance, we show, that the dynamics of low-rank adaptation is close to that of differentially private, fine-tuning of the adapters. Finally, using Johnson-Lindenstrauss lemma, we show, that when augmented with gradient scaling, low-rank adaptation is very close to, performing DPSGD algorithm with a fixed noise scale to fine-tune the adapters., These theoretical findings suggest that unlike other existing fine-tuning algorithms,, low-rank adaptation provides privacy w.r.t the fine-tuning data implicitly.
Authors:
Habib Hajimolahoseini, Shuangyue Wen, Walid Ahmed, Yang Liu
Abstract:In this paper, we present a comprehensive study and propose several novel tech-, niques for implementing 3D convolutional blocks using 2D and/or 1D convolutions, with only 4D and/or 3D tensors. Our motivation is that 3D convolutions with 5D, tensors are computationally very expensive and they may not be supported by some, of the edge devices used in real-time applications such as robots. The existing, approaches mitigate this by splitting the 3D kernels into spatial and temporal do-, mains, but they still use 3D convolutions with 5D tensors in their implementations., We resolve this issue by introducing some appropriate 4D/3D tensor reshaping as, well as new combination techniques for spatial and temporal splits. The proposed, implementation methods show significant improvement both in terms of efficiency, and accuracy. The experimental results confirm that the proposed spatio-temporal, processing structure outperforms the original model in terms of speed and accuracy, using only 4D tensors with fewer parameters.
Authors:
Moshe Kimhi, Avi Mendelson, Idan Kashani, Chaim Baskin
Abstract:The widely used ReLU is favored for its hardware efficiency, as the implementation, at inference is a one bit sign case, yet suffers from issues such as the “dying ReLU”, problem, where during training, neurons fail to activate and constantly remain, at zero, as highlighted by Lu et al. [16]. Traditional approaches to mitigate this, issue often introduce more complex and less hardware-friendly activation func-, tions. In this work, we propose a Hysteresis Rectified Linear Unit (HeLU), an, efficient activation function designed to address the “dying ReLU” problem with, minimal complexity. Unlike traditional activation functions with fixed thresholds, for training and inference, HeLU employs a variable threshold that refines the, backpropagation. This refined mechanism allows simpler activation functions to, achieve competitive performance comparable to their more complex counterparts, without introducing unnecessary complexity or requiring inductive biases. Em-, pirical evaluations demonstrate that HeLU enhances model generalization across, diverse datasets, offering a promising solution for efficient and effective inference, suitable for a wide range of neural network architectures.
Authors:
Oscar Key, Luka Ribar, Alberto Cattaneo, Luke Hudlass-Galley, Douglas Orr
Abstract:We present an evaluation of bucketed approximate top-k algorithms. Computing top-k exactly suffers from limited parallelism, because the k largest values must be aggregated along the vector, thus is not well suited to computation on highlyparallel machine learning accelerators. By relaxing the requirement that the top-k is exact, bucketed algorithms can dramatically increase the parallelism available by independently computing many smaller top-k operations. We explore the design choices of this class of algorithms using both theoretical analysis and empirical evaluation on downstream tasks. Our motivating examples are sparsity algorithms for language models, which often use top-k to select the most important parameters or activations. We also release a fast bucketed top-k implementation for PyTorch
Authors:
Alessio Devoto, Yu Zhao, Simone Scardapane, Pasquale Minervini
Abstract:The deployment of large language models (LLMs) is often hindered by the extensive memory requirements of the Key-Value (KV) cache, especially as context lengths increase. Existing approaches to reduce the KV Cache size involve either finetuning the model to learn a compression strategy or leveraging attention scores to reduce the sequence length. We analyse the attention distributions in decoder only Transformers-based models and observe that attention allocation patterns stay consistent across most layers. Surprisingly, we find a clear correlation between the L2 norm and the attention scores over cached KV pairs, where a low L2 norm of a key embedding usually leads to a high attention score during decoding. This finding indicates that the influence of a KV pair is potentially determined by the key embedding itself before being queried. Based on this observation, we compress the KV Cache based on the L2 norm of key embeddings. Our experimental results show that this simple strategy can reduce the KV Cache size by 50% on language modelling and needle-in-a-haystack tasks and 90% on passkey retrieval tasks without losing accuracy. Moreover, without relying on the attention scores, this approach remains compatible with FlashAttention, enabling broader applicability.
Authors:
Lianming Huang, Shangyu Wu, Yufei Cui, Ying Xiong, Xue Liu, Tei-Wei Kuo, Nan Guan, Chun Jason Xue
Abstract:Deploying large language model inference remains challenging due to their high, computational overhead. Early exiting optimizes model inference by adaptively, reducing the number of inference layers. Existing methods typically train internal, classifiers to determine whether to exit at intermediate layers. However, such, classifier-based early exiting frameworks require significant effort to train the, classifiers while can only achieve comparable performance at best. To address, these limitations, this paper proposes RAEE, a robust Retrieval-Augmented Early, Exiting framework for efficient inference. First, this paper demonstrates that the, early exiting problem can be modeled as a distribution prediction problem, where, the distribution is approximated using similar data’s exiting information. Then,, this paper details the process of collecting exiting information to build the retrieval, database. Finally, based on the pre-built retrieval database, RAEE leverages the, retrieved similar data’s exiting information to guide the backbone model to exit, at the layer, which is predicted by the approximated distribution. Experimental, results demonstrate that the proposed RAEE can significantly accelerate inference., More importantly, RAEE can also achieve a robust zero-shot performance on 8, downstream tasks.
Authors:
Agniv Sharma, Jonas Geiping
Abstract:Transformers are widely used across various applications, many of which yield, sparse or partially filled attention matrices. Examples include attention masks, designed to reduce the quadratic complexity of attention, sequence packing tech-, niques, and recent innovations like tree masking for fast validation in MEDUSA., Despite the inherent sparsity in these matrices, the state-of-the-art algorithm Flash, Attention still processes them with quadratic complexity as though they were dense., In this paper, we introduce Binary Block Masking, a highly efficient modifica-, tion that enhances Flash Attention by making it mask-aware. We further propose, two optimizations: one tailored for masks with contiguous non-zero patterns and, another for extremely sparse masks. Our experiments on attention masks derived, from real-world scenarios demonstrate up to a 9x runtime improvement. The, implementation will be publicly released to foster further research and application.
Authors:
Jacob K. Christopher, Brian R. Bartoldson, Tal Ben-Nun, Michael Cardei, Bhavya Kailkhura, Ferdinando Fioretto
Abstract:Speculative decoding has emerged as a widely adopted method to accelerate large, language model inference without sacrificing the quality of the model outputs., While this technique has facilitated notable speed improvements by enabling paral-, lel sequence verification, its efficiency remains inherently limited by the reliance on, incremental token generation in existing draft models. To overcome this limitation,, this paper proposes an adaptation of speculative decoding which uses discrete, diffusion models to generate draft sequences. This allows parallelization of both, the drafting and verification steps, providing significant speedups to the inference, process. Our proposed approach, Speculative Diffusion Decoding (SpecDiff), is val-, idated on standard language generation benchmarks and empirically demonstrated, to provide up to 7.2x speedups over standard generation processes and up to, 1.75x speedups over existing speculative decoding approaches.
Authors:
Keivan Alizadeh, Iman Mirzadeh, Hooman Shahrokhi, Dmitry Belenko, Chenfan Sun, Minsik Cho, Mohammad Sekhavat, Moin Nabi, Mehrdad Farajtabar
Abstract:Large Language Models (LLMs) typically generate outputs token by token using a fixed compute budget, leading to inefficient resource utilization. To address this shortcoming, recent advancements in mixture of expert (MoE) models, speculative decoding, and early exit strategies leverage the insight that computational demands can vary significantly based on the complexity and nature of the input. However, identifying optimal routing patterns for dynamic execution remains an open challenge, limiting the full potential of these adaptive methods. To address this need, we study adaptive computation in LLMs more systematically. We propose a novel framework that integrates smaller auxiliary modules within each Feed-Forward Network layer of the LLM. This design enables dynamic routing of tokens based on task complexity: tokens can be processed by either the small or big modules at each layer, or even bypass certain layers entirely. This allows us to introduce a novel notion of a token’s difficulty, defined by its potential to benefit from additional computational resources. Importantly, by employing oracles to identify optimal patterns of adaptive computations, we gain valuable insights into the internal workings of LLMs and the routing processes in a simplified heterogeneous MoE setup. We show that trained routers operate differently from oracles and often yield suboptimal solutions. Notably, activating a large module in just one layer outperforms models that use large modules across all layers, underscoring the gap between practical implementations of routing in MoE models and theoretical optima for adaptive computation.
Authors:
Adithya Vasudev
Abstract:The Lottery Ticket hypothesis proposes that ideal, sparse subnetworks, called, lottery tickets, exist in untrained dense neural networks. The Early Bird hypothesis, proposes an efficient algorithm to find these winning lottery tickets in convolutional, neural networks, using the novel concept of distance between subnetworks to detect, convergence in the subnetworks of a model. However, this approach overlooks, unchanging groups of unimportant neurons near the search’s end. We propose, WORM, a method that exploits these static groups by truncating their gradients,, forcing the model to rely on other neurons. Experiments show WORM achieves, faster ticket identification during training on convolutional neural networks, de-, spite the additional computational overhead, when compared to EarlyBird Search., Additionally, WORM-pruned models lose less accuracy during pruning and re-, cover accuracy faster, improving the robustness of a given model. Furthermore,, WORM is also able to generalize the Early Bird hypothesis reasonably well to, larger models, such as transformers, displaying its flexibility to adapt to more, complex architectures.
Authors:
Sayeh Sharify, Utkarsh Saxena, Zifei Xu, Wanzin Yazar, Ilya Soloveychik, Xin Wang
Abstract:Large Language Models (LLMs) have distinguished themselves with outstanding, performance in complex language modeling tasks, yet they come with signifi-, cant computational and storage challenges. This paper explores the potential of, quantization to mitigate these challenges. We systematically study the combined, application of three well-known post-training techniques, SmoothQuant, AWQ, and, GPTQ, and provide a comprehensive analysis of their interactions and implications, for advancing LLM quantization. We enhance the versatility of these methods by, enabling quantization to microscaling (MX) formats, extending the applicability, of these PTQ algorithms beyond their original fixed-point format targets. We, show that combining different PTQ methods enables us to quantize models to 4-bit, weights and 8-bit activations using the MXINT format with negligible accuracy, loss compared to the uncompressed baseline.
Authors:
Saleh Ashkboos, Iman Mirzadeh, Moin Nabi, Keivan Alizadeh, Mehrdad Farajtabar, Mohammad Hossein Sekhavat, Fartash Faghri
Abstract:While large language models (LLMs) dominate the AI landscape, Small-scale large, Language Models (SLMs) are gaining attention due to cost and efficiency demands, from consumers. However, there is limited research on the training behavior and, computational requirements of SLMs. In this study, we explore the computational, bottlenecks of training SLMs (up to 2B parameters) by examining the effects, of various hyperparameters and configurations, including GPU type, batch size,, model size, communication protocol, attention type, and the number of GPUs. We, assess these factors on popular cloud services using metrics such as loss per dollar, and tokens per second 2 . Our findings aim to support the broader adoption and, optimization of language model training for low-resource AI research institutes.
Authors:
Neal Lawton, Jack FitzGerald, Aishwarya Padmakumar, Anoop Kumar, Judith Gaspers, Greg Ver Steeg, Aram Galstyan
Abstract:QLoRA reduces the memory-cost of fine-tuning a large language model (LLM), with LoRA by quantizing the base LLM. However, quantization introduces quan-, tization errors that negatively impact model performance after fine-tuning. In, this paper we introduce QuAILoRA, a quantization-aware initialization for LoRA, that mitigates this negative impact by decreasing quantization errors at initial-, ization. Our method spends a small amount of computational overhead to com-, pute this quantization-aware initialization, without increasing the memory-cost, of fine-tuning. We evaluate our method on several causal language modeling and, downstream evaluation tasks using several different model sizes and families. We, observe that almost all LLMs fined-tuned with QuAILoRA achieve better valida-, tion perplexity. When evaluated on downstream tasks, we find that QuAILoRA, yields improvements proportional to the negative effect of quantization error. On, average, applying QuAILoRA to 4-bit QLoRA models yields 75% of the validation, perplexity decrease and 86% of the downstream task accuracy increase as doubling, the quantization precision to 8-bit, without increasing GPU memory utilization, during fine-tuning.
Authors:
Kaavya Chaparala, Bruce Torres Fischer, Guido Zarrella, Larry Kimura, Oiwi Parker Jones
Abstract:In this paper we address the challenge of improving Automatic Speech Recognition, (ASR) for a low-resource language, Hawaiian, by incorporating large amounts, of independent text data into an ASR foundation model, Whisper. To do this,, we train an external language model (LM) on ⇠1.5M words of Hawaiian text., We then use the LM to rescore Whisper and compute word error rates (WERs), on a manually curated test set of labeled Hawaiian data. As a baseline, we use, Whisper without an external LM. Experimental results reveal a small but significant, improvement in WER when ASR outputs are rescored with a Hawaiian LM. The, results support leveraging all available data in the development of ASR systems for, underrepresented languages.
Authors:
Aashiq Muhamed, Jiarui Liu, Mona T. Diab, Virginia Smith
Abstract:Large foundation models (LFMs) power a diverse range of applications, but, their deployment often requires adapting model size and performance to specific, hardware constraints and latency requirements. Existing approaches rely on, training independent models of various sizes, leading to storage redundancy,, inconsistent behavior across sizes, and limited scalability. This work investigates, post-training techniques for inducing elasticity into pre-trained LFMs, enabling, dynamic adaptation of model size during inference based on specific needs. We, frame this as decomposing LFM weight matrices into sparsely activating factors., While naive decompositions like weight SVD struggle to maintain performance, across complex tasks while inducing the desired nested sub-structures, we propose, two novel methods: SparseDecomp, which exploits sparse neuron activations in, feed-forward networks to conditionally select decoder rows; and RankDecomp,, which leverages the basis-agnostic nature of Transformers for low-rank weight, decomposition. Integrating SparseDecomp and RankDecomp with GritLM-7B,, a state-of-the-art LFM excelling in both generative and embedding tasks, we, conduct a comparative analysis. Our results demonstrate that these approaches, offer complementary benefits. SparseDecomp maintains robust performance across, a wider range of sparsity levels, achieving average speedups of up to 4.6% with, 25% sparsity. RankDecomp, conversely, yields more significant latency reduction,, reaching a speedup of 22.2% at 25% sparsity, but exhibits greater sensitivity, to increasing sparsity. This study provides valuable insights into leveraging, post-training weight decomposition for developing efficient and adaptable LFMs,, paving the way for future research on creating elastic and resource-aware models.
Authors:
Yongchang Hao, Yanshuai Cao, Lili Mou
Abstract:The performance of neural networks improves when more parameters are used., However, the model sizes are constrained by the available on-device memory, during training and inference. Although applying techniques like quantization, can alleviate the constraint, they suffer from performance degradation. In this, work, we introduce NeuZip, a new weight compression scheme based on the, entropy of floating-point numbers in neural networks. With NeuZip, we are able to, achieve memory-efficient training and inference without sacrificing performance., Notably, we significantly reduce the memory footprint of training a Llama-3 8B, model from 31GB to less than 16GB, while keeping the training dynamics fully, unchanged. In inference, our method can reduce memory usage by more than half, while maintaining near-lossless performance. Our code is publicly available.
Authors:
Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, Murali Annavaram
Abstract:Large Language Models (LLMs) have demonstrated exceptional performance in, automating various tasks, such as text generation and summarization. Currently, LLMs are trained and fine-tuned on large cloud server. Deploying and fine-tuning, these models on resource-constrained edge devices remains a significant challenge, due to their substantial memory and computational requirements. This paper, introduces a resource-efficient zeroth-order optimization approach that lowers the, barriers for fine-tuning LLMs in such constrained environments. Our method, features a parallelized randomized gradient estimation (P-RGE) technique, which, performs gradient estimation with high parallel efficiency. P-RGE leverages outer-, loop and inner-loop parallelization to perform multiple function queries and forward, passes in parallel, reducing the wall-clock end-to-end training time. By integrating, this technique with parameter-efficient fine-tuning methods (e.g., LoRA) and on-, device inference engines (e.g., ExecuTorch), we demonstrate efficient fine-tuning, of LLMs on both server-side and edge devices. Experiments show that P-RGE, achieves significant runtime speedups and memory savings while maintaining, fine-tuning accuracy, which paves the way for more practical deployment of LLMs, in real-time, on-device applications.
Authors:
Hossein Rajabzadeh, Aref Jafari, Aman Sharma, Benyamin Jami, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh
Abstract:Large Language Models (LLMs), with their increasing depth and number of pa-, rameters, have demonstrated outstanding performance across a variety of natu-, ral language processing tasks. However, this growth in scale leads to increased, computational demands, particularly during inference and fine-tuning. To address, these challenges, we introduce EchoAtt, a novel framework aimed at optimiz-, ing transformer-based models by analyzing and leveraging the similarity of atten-, tion patterns across layers. Our analysis reveals that many inner layers in LLMs,, especially larger ones, exhibit highly similar attention matrices. By exploiting, this similarity, EchoAtt enables the sharing of attention matrices in less critical, layers, significantly reducing computational requirements without compromising, performance. We incorporate this approach within a knowledge distillation setup,, where a pre-trained teacher model guides the training of a smaller student model., The student model selectively shares attention matrices in layers with high sim-, ilarity while inheriting key parameters from the teacher. Our best results with, TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15%,, training speed by 25%, and reduces the number of parameters by approximately, 4%, all while improving zero-shot performance. These findings highlight the po-, tential of attention matrix sharing to enhance the efficiency of LLMs, making them, more practical for real-time and resource-limited applications.
Authors:
Ali Shiraee Kasmaee, Mohammad Khodadad, Mohammad Arshi Saloot, Nick Sherck, Stephen Dokas, Hamidreza Mahyar, Soheila Samiee
Abstract:Recent advancements in language models have started a new era of superior, information retrieval and content generation, with embedding models playing, an important role in optimizing data representation efficiency and performance., While benchmarks like the Massive Text Embedding Benchmark (MTEB) have, standardized the evaluation of general domain embedding models, a gap remains, in specialized fields such as chemistry, which require tailored approaches due, to domain-specific challenges. This paper introduces a novel benchmark, the, Chemical Text Embedding Benchmark (ChemTEB), designed specifically for, the chemical sciences. ChemTEB addresses the unique linguistic and semantic, complexities of chemical literature and data, offering a comprehensive suite of tasks, on chemical domain data. Through the evaluation of 34 open-source and proprietary, models using this benchmark, we illuminate the strengths and weaknesses of, current methodologies in processing and understanding chemical information. Our, work aims to equip the research community with a standardized, domain-specific, evaluation framework, promoting the development of more precise and efficient, NLP models for chemistry-related applications. Furthermore, it provides insights, into the performance of generic models in a domain-specific context. ChemTEB, comes with open-source code 1 and data 2 , contributing further to its accessibility, and utility.
Authors:
Zifei Xu, Alexander Lan, Wanzin Yazar, Tristan Webb, Sayeh Sharify, Xin Wang
Abstract:Generalization abilities of well-trained large language models (LLMs) are known, to scale predictably as a function of model size. In contrast to the existence, of practical scaling laws governing pre-training, the quality of LLMs after post-, training compression remains highly unpredictable, often requiring case-by-case, validation in practice. In this work, we attempted to close this gap for post-training, weight quantization of LLMs by conducting a systematic empirical study on, multiple LLM families quantized to numerous low-precision tensor data types using, popular weight quantization techniques. We identified key scaling factors pertaining, to characteristics of the local loss landscape, based on which the performance of, quantized LLMs can be reasonably well predicted by a statistical model.
Authors:
Yanhong Li, Karen Livescu, Jiawei Zhou
Abstract:We introduce Chunk-Distilled Language Modeling (CD-LM), an approach to, text generation that addresses two challenges in current large language models, (LLMs): the inefficiency of token-level generation, and the difficulty of adapting, to new data and knowledge. Our method combines deep network-based LLMs, with a straightforward retrieval module, which allows the generation of multi-, token text chunks at a single decoding step. Our retrieval framework enables, flexible construction of model- or domain-specific datastores, either leveraging, the internal knowledge of existing models, or incorporating expert insights from, human-annotated corpora. This adaptability allows for enhanced control over the, language model’s distribution without necessitating additional training. We present, the CD-LM formulation along with performance metrics demonstrating its ability, to improve language model performance and efficiency across a diverse set of, downstream tasks.
Authors:
Gautham Krishna Gudur, Edison Thomaz
Abstract:Audio classification tasks like keyword spotting and acoustic event detection often, require large labeled datasets, which are computationally expensive and impractical, for resource-constrained devices. While active learning techniques attempt to, reduce labeling efforts by selecting the most informative samples, they struggle, with scalability in real-world scenarios involving thousands of audio segments., In this paper, we introduce an approach that leverages dataset distillation as an, alternative strategy to active learning to address the challenge of data efficiency, in real-world audio classification tasks. Our approach synthesizes compact, high-, fidelity coresets that encapsulate the most critical information from the original, dataset, significantly reducing the labeling requirements while offering competitive, performance. Through experiments on three benchmark datasets – Google Speech, Commands, UrbanSound8K, and ESC-50, our approach achieves up to a ∼3,000x, reduction in data points, and requires only a negligible fraction of the original, training data while matching the performance of popular active learning baselines.
Authors: Abstract:
Transformer-based Large Language Models (LLMs) have become increasingly, important. However, due to the quadratic time complexity of attention computa-, tion, scaling LLMs to longer contexts incurs extremely slow inference speed and, high GPU memory consumption for caching key-value (KV) vectors. This paper, proposes RetrievalAttention, a training-free approach to both accelerate attention, computation and reduce GPU memory consumption. By leveraging the dynamic, sparsity of attention mechanism, RetrievalAttention proposes to build approximate, nearest neighbor search (ANNS) indexes for KV vectors in CPU memory and, retrieve the most relevant ones through vector search during generation. Unfortu-, nately, we observe that the off-the-shelf ANNS indexes are often ineffective for, such retrieval tasks due to the out-of-distribution (OOD) between query vectors, and key vectors in the attention mechanism. RetrievalAttention addresses the OOD, challenge by designing an attention-aware vector search algorithm that can adapt to, the distribution of query vectors. Our evaluation demonstrates that RetrievalAtten-, tion achieves near full attention accuracy while only requiring access to 1–3% of, the data. This leads to a significant reduction in the inference cost of long-context, LLMs, with a much lower GPU memory footprint. In particular, RetrievalAttention, only needs a single NVIDIA RTX4090 (24GB) to serve 128K tokens for LLMs, with 8B parameters, which is capable of generating one token in 0.188 seconds.
Authors:
Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, Lili Qiu
Abstract:Long-context Large Language Models (LLMs) have unlocked numerous possibili-, ties for downstream applications, many of which involve multiple requests sharing, the same input context. Recent inference frameworks like vLLM and SGLang,, as well as LLMs providers such as OpenAI, Google and Anthropic, have em-, ployed prefix caching techniques to accelerate multi-requests with shared context., However, existing long-context methods are primarily evaluated on single query, testing, failing to demonstrate their true capability in real-world applications that, often require KV cache reuse for follow-up queries. To address this gap, we intro-, duce SharedContextBench, a comprehensive long-context benchmark to reveal, how lossy are long-context methods in KV cache reuse scenarios. Specifically, it, encompasses 12 tasks with two shared context modes, covering four categories, of long-context abilities: string retrieval, semantic retrieval, global information, processing, and multi-task capabilities. Using our benchmark, we evaluated five cat-, egories of long-context solutions, including Gated Linear RNNs (Codestal-Mamba),, Mamba-Attention hybrids (Jamba-1.5-Mini), and efficient methods like sparse at-, tention, KV cache compression, and prompt compression, on six transformer-based, long-context LLMs: Llama-3.1-8B/70B, Qwen2.5-72B/32B, Llama-3-8B-262K,, and GLM-4-9B. Our findings show that sub-O(n) memory methods often struggle, to maintain accuracy in multi-turn scenarios, while sparse encoding methods with, O(n) memory and sub-O(n2 ) computation in prefilling generally perform well., Additionally, dynamic sparse patterns in prefilling often produce more expressive, memory (KV cache) compared to static methods, and layer-level sparsity in hybrid, architectures reduces memory usage while yielding promising results.
Authors:
Niklas Schmidinger, Lisa Schneckenreiter, Philipp Seidl, Johannes Schimunek, Pieter-Jan Hoedt, Johannes Brandstetter, Andreas Mayr, Sohvi Luukkonen, Sepp Hochreiter, Günter Klambauer
Abstract:Language models for biological and chemical sequences enable crucial applications, such as drug discovery, protein engineering, and precision medicine. Currently,, these language models are predominantly based on Transformer architectures., While Transformers have yielded impressive results, their quadratic runtime de-, pendency on sequence length complicates their use for long genomic sequences, and in-context learning on proteins and chemical sequences. Recently, the re-, current xLSTM architecture has been shown to perform favorably compared to, Transformers and modern state-space models (SSMs) in the natural language do-, main. Similar to SSMs, xLSTMs have linear runtime dependency and allow for, constant-memory decoding at inference time, which makes them prime candidates, for modeling long-range dependencies in biological and chemical sequences. In, this work, we tailor xLSTM towards these domains and we propose a suite of, language models called Bio-xLSTM. Extensive experiments in three large domains,, genomics, proteins, and chemistry, were performed to assess xLSTM’s ability to, model biological and chemical sequences. The results show that Bio-xLSTM is, a highly proficient generative model for DNA, protein, and chemical sequences,, learns rich representations, and can perform in-context learning for proteins and, small molecules.
Authors:
Jort Vincenti, Karim Abdel Sadek, Joan Velja, Matteo Nulli, Metod Jazbec
Abstract:Increasing the size of large language models (LLMs) has been shown to lead to, better performance. However, this comes at the cost of slower and more expensive, inference. Early-exiting is a promising approach for improving the efficiency of, LLM inference by enabling next token prediction at intermediate layers. Yet, the, large vocabulary size in modern LLMs makes the confidence estimation required, for exit decisions computationally expensive, diminishing the efficiency gains., To address this, we propose dynamically pruning the vocabulary at test time for, each token. Specifically, the vocabulary is pruned at one of the initial layers, and, the smaller vocabulary is then used throughout the rest of the forward pass. Our, experiments demonstrate that such post-hoc dynamic vocabulary pruning improves, the efficiency of confidence estimation in early-exit LLMs while maintaining, competitive performance.
Authors:
Ofir Zafrir, Igor Margulis, Dorin Shteyman, Guy Boudoukh
Abstract:Speculative Decoding has gained popularity as an effective technique for accelerating the auto-regressive inference process of Large Language Models (LLMs). However, Speculative Decoding entirely relies on the availability of efficient draft models, which are often lacking for many existing language models due to a stringent constraint of vocabulary incompatibility. In this work we introduce FastDraft, a novel and efficient approach for pre-training and aligning a draft model to any large language model by incorporating efficient pre-training, followed by finetuning over synthetic datasets generated by the target model. We demonstrate FastDraft by training two highly parameter efficient drafts for the popular Phi-3- mini and Llama-3.1-8B models. Using FastDraft, we were able to produce a draft with approximately 10 billion tokens on a single server with 8 accelerators in under 24 hours. Our results show that the draft model achieves impressive results in key metrics of acceptance rate, block efficiency and up to 3x memory bound speed up when evaluated on code completion and up to 2x in summarization, text completion and instruction tasks. Due to its high quality, FastDraft unlocks large language models inference on AI-PC and other edge-devices.
Authors:
Tushar Shinde, Ritika Jain, Avinash Kumar Sharma
Abstract:Speech Emotion Recognition (SER) systems are essential in advancing human-, machine interaction. While deep learning models have shown substantial success in, SER by eliminating the need for handcrafted features, their high computational and, memory requirements, alongside intensive hyper-parameter optimization, limit their, deployment on resource-constrained edge devices. To address these challenges, we, introduce an optimized and computationally efficient Multilayer Perceptron (MLP)-, based classifier within a custom SER framework. We further propose a novel,, layer-wise adaptive quantization scheme that compresses the model by adjusting bit-, width precision according to layer importance. This layer importance is calculated, based on statistical measures such as parameter proportion, entropy, and weight, variance within each layer. Our approach achieves an optimal balance between, model size reduction and performance retention, ensuring that the quantized model, maintains accuracy within acceptable limits. Traditional fixed-precision methods,, while computationally simple, are less effective at reducing model size without, compromising performance. In contrast, our scheme provides a more interpretable, and computationally efficient solution. We evaluate the proposed model on standard, SER datasets using features such as Mel-Frequency Cepstral Coefficients (MFCC),, Chroma, and Mel-spectrogram. Experimental results demonstrate that our adaptive, quantization method achieves performance competitive with state-of-the-art models, while significantly reducing model size, making it highly suitable for deployment, on edge devices.
Authors:
Rongzhi Zhang, Kuang Wang, Liyuan Liu, Shuohang Wang, Hao Cheng, Chao Zhang, Yelong Shen
Abstract:The Key-Value (KV) cache is a crucial component in serving transformer-based, autoregressive large language models (LLMs), enabling faster inference by storing, previously computed KV vectors. However, its memory consumption scales lin-, early with sequence length and batch size, posing a significant bottleneck in LLM, deployment. Existing approaches to mitigate this issue include: (1) efficient atten-, tion variants integrated in upcycling stages, which requires extensive parameter, tuning thus unsuitable for pre-trained LLMs; (2) KV cache compression at test, time, primarily through token eviction policies, which often overlook inter-layer, dependencies and can be task-specific., This paper introduces an orthogonal approach to KV cache compression. We, propose a low-rank approximation of KV weight matrices, allowing for plug-, in integration with existing transformer-based LLMs without model retraining., To effectively compress KV cache at the weight level, we adjust for layerwise, sensitivity and introduce a progressive compression strategy, which is supported by, our theoretical analysis on how compression errors accumulate in deep networks., Our method is designed to function without model tuning in upcycling stages or, task-specific profiling in test stages. Extensive experiments with LLaMA models, ranging from 8B to 70B parameters across various tasks show that our approach, significantly reduces the GPU memory footprint while maintaining performance.
Authors:
Youngseog Chung, Dhruv Malik, Jeff Schneider, Yuanzhi Li, Aarti Singh
Abstract:Authors:
MohammadAli SadraeiJavaeri, Ehsaneddin Asgari, Alice Carolyn McHardy, Hamid Reza Rabiee
Abstract:Soft prompt tuning techniques have recently gained traction as an effective strat-, egy for the parameter-efficient tuning of pretrained language models, particularly, minimizing the required adjustment of model parameters. Despite their growing, use, achieving optimal tuning with soft prompts, especially for smaller datasets,, remains a substantial challenge. This study makes two contributions in this do-, main: (i) we introduce S UPER P OS -P ROMPT, a new reparameterization technique, employing the superposition of multiple pretrained vocabulary embeddings to, improve the learning of soft prompts. Our experiments across several GLUE and, SuperGLUE benchmarks consistently highlight S UPER P OS -P ROMPT’s superior-, ity over Residual Prompt tuning, exhibiting an average score increase of +6.4, in T5-Small and +5.0 in T5-Base along with a faster convergence. Remarkably,, S UPER P OS -P ROMPT occasionally outperforms even full fine-tuning methods. (ii), Additionally, we demonstrate enhanced performance and rapid convergence by, omitting dropouts from the frozen network, yielding consistent improvements, across various scenarios and tuning methods.
Authors:
Soumajyoti Sarkar, Leonard Lausen, Thomas Brox, Volkan Cevher, Sheng Zha, George Karypis
Abstract:Sparse Mixture of Expert (SMoE) models have emerged as a scalable alterna-, tive to dense models in language modeling. These models use conditionally ac-, tivated feedforward subnetworks in transformer blocks, allowing for a separation, between total model parameters and per-example computation. However, large, token-routed SMoE models face a significant challenge: during inference, the en-, tire model must be used for a sequence or a batch, resulting in high latencies, in a distributed setting that offsets the advantages of per-token sparse activation., Our research explores task-specific model pruning to inform decisions about de-, signing SMoE architectures, mainly modulating the choice of expert counts in, pretraining. We investigate whether such pruned models offer advantages over, smaller SMoE models trained from scratch, when evaluating and comparing them, individually on tasks. To that end, we introduce an adaptive task-aware pruning, technique UNCURL to reduce the number of experts per MoE layer in an offline, manner post-training. Our findings reveal a threshold pruning factor for the re-, duction that depends on the number of experts used in pretraining, above which,, the reduction starts to degrade model performance. These insights contribute to, our understanding of model design choices when pretraining with SMoE architec-, tures, particularly useful when considering task-specific inference optimization, for later stages.
Authors:
Costin-Andrei Oncescu, Sanket Purandare, Stratos Idreos, Sham Kakade
Abstract:While transformers have been at the core of most recent advancements in sequence, generative models, their computational cost remains quadratic in sequence length., Several subquatratic architectures have been proposed to address this computational, issue. Some of them, including long convolution sequence models (LCSMs), such, as Hyena, address this issue at training time but remain quadratic during inference., We propose a method for speeding up LCSMs’ inference to quasilinear time, iden-, tify the key properties that make this possible, and propose a general framework, that exploits these. Our approach, inspired by previous work on relaxed polynomial, interpolation, is based on a tiling which helps decrease memory movement and, share computation. It has the added benefit of allowing for almost complete paral-, lelization across layers of the position-mixing part of the architecture. Empirically,, we provide a proof of concept implementation for Hyena-like settings, which gets, up to 4× improvement over standard inference.
Accepted papers




Rephrasing natural text data with different languages and quality levels for Large Language Model pre-training












AdaEDL: Early Draft Stopping for Speculative Decoding of Large Language Models via an Entropy-based Lower Bound on Token Acceptance Probability

OnlySportsLM: Optimizing Sports-Domain Language Models with SOTA Performance under Billion Parameters
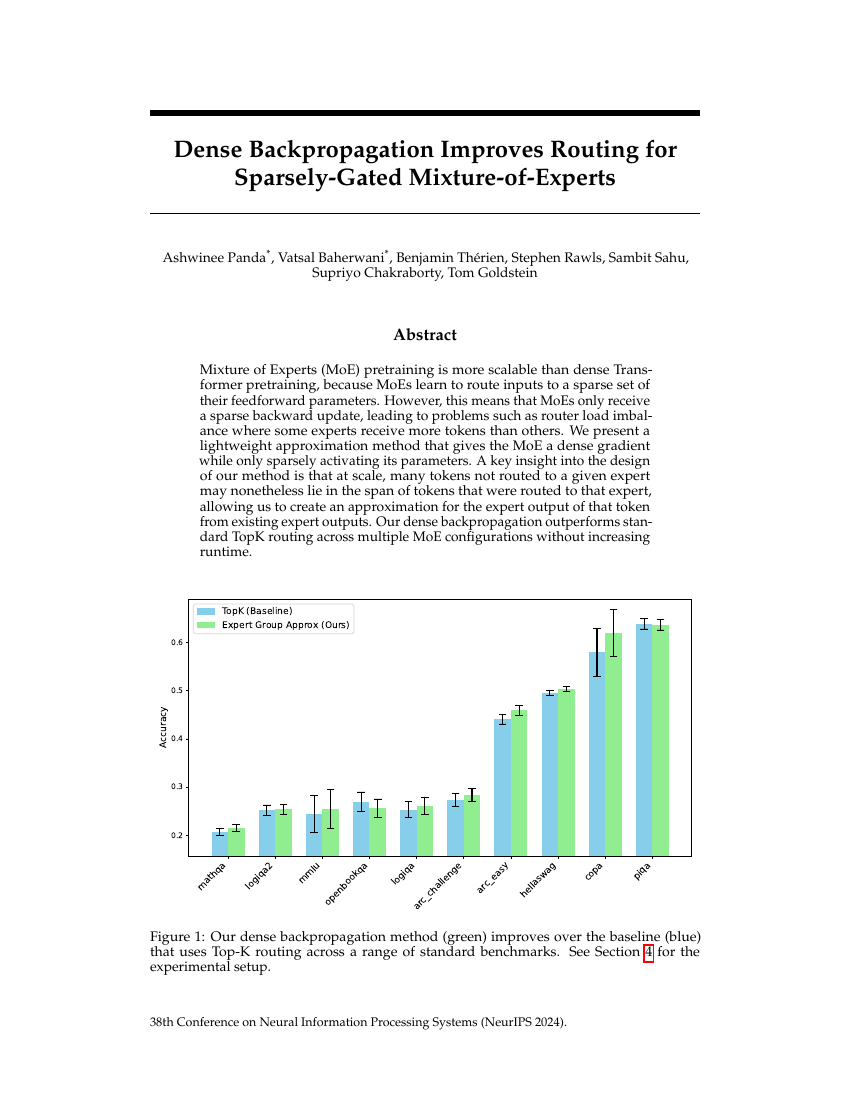




Less is Enough: Adapting Pre-trained Vision Transformers for Audio-Visual Speaker Verification









Approximations may be all you need: Towards Pre-training LLMs with Low-Rank Decomposition and Optimizers










Inferring from Logits: Exploring Best Practices for Decoding-Free Generative Candidate Selection








Enhanced label noise robustness through early adaptive filtering for the self-supervised speaker verification task




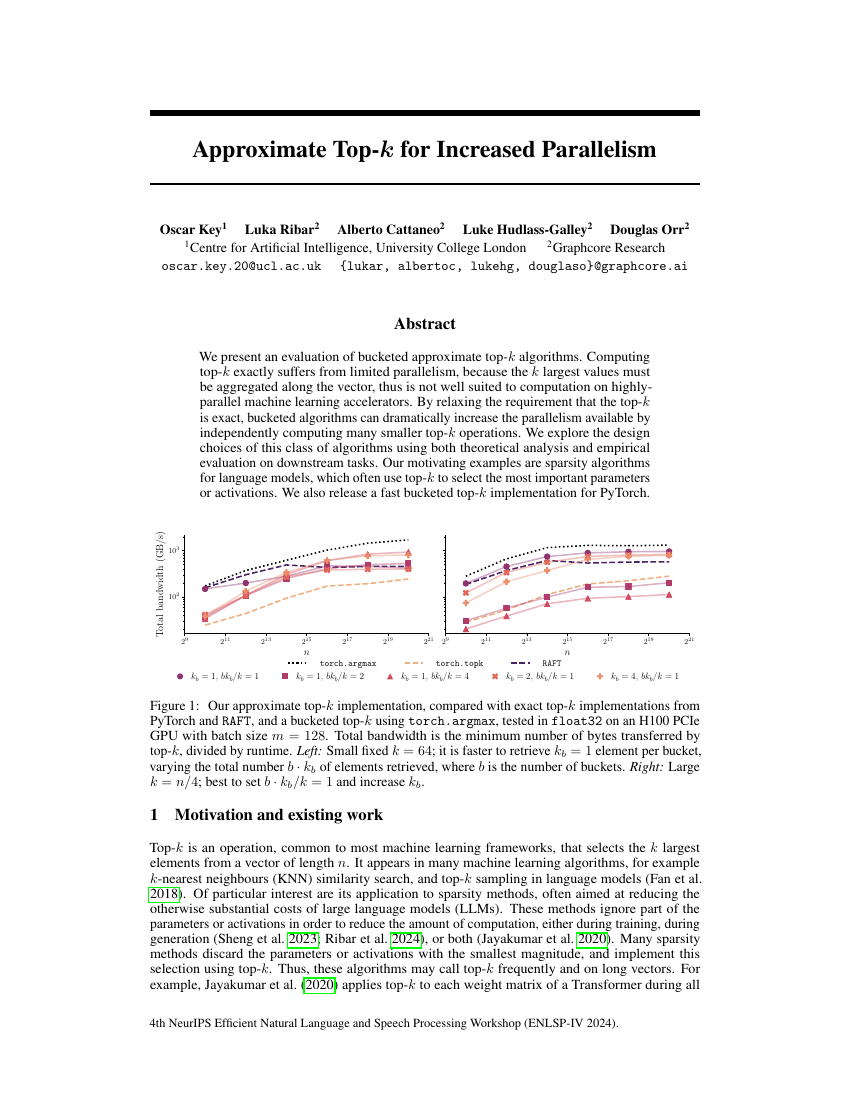















ChemTEB: Chemical Text Embedding Benchmark, an Overview of Embedding Models Performance & Efficiency on a Specific Domain



Dataset Distillation for Audio Classification: A Data-Efficient Alternative to Active Learning



Bio-xLSTM: Generative modeling, representation and in-context learning of biological and chemical sequences



Lightweight Neural Networks for Speech Emotion Recognition using Layer-wise Adaptive Quantization


SuperPos-Prompt: Enhancing Soft Prompt Tuning of Language Models with Superposition of Multi Token Embeddings

